技术迭代日新月异,AI 赛道竞争白热化,自己的技能却停滞不前,薪资原地踏步,晋升通道被牢牢卡死?

深知AI是未来十年最大风口,LLM 算法工程师更是稀缺高薪岗位,却面对 Transformer、RLHF、提示工程等复杂技术栈无从下手,自学效率低、效果差,越学越迷茫?
渴望敲开头部科技企业、AI 独角兽的大门,却因缺乏真实项目实战经验、技能体系零散,简历投出去石沉大海,连面试机会都难以获得?

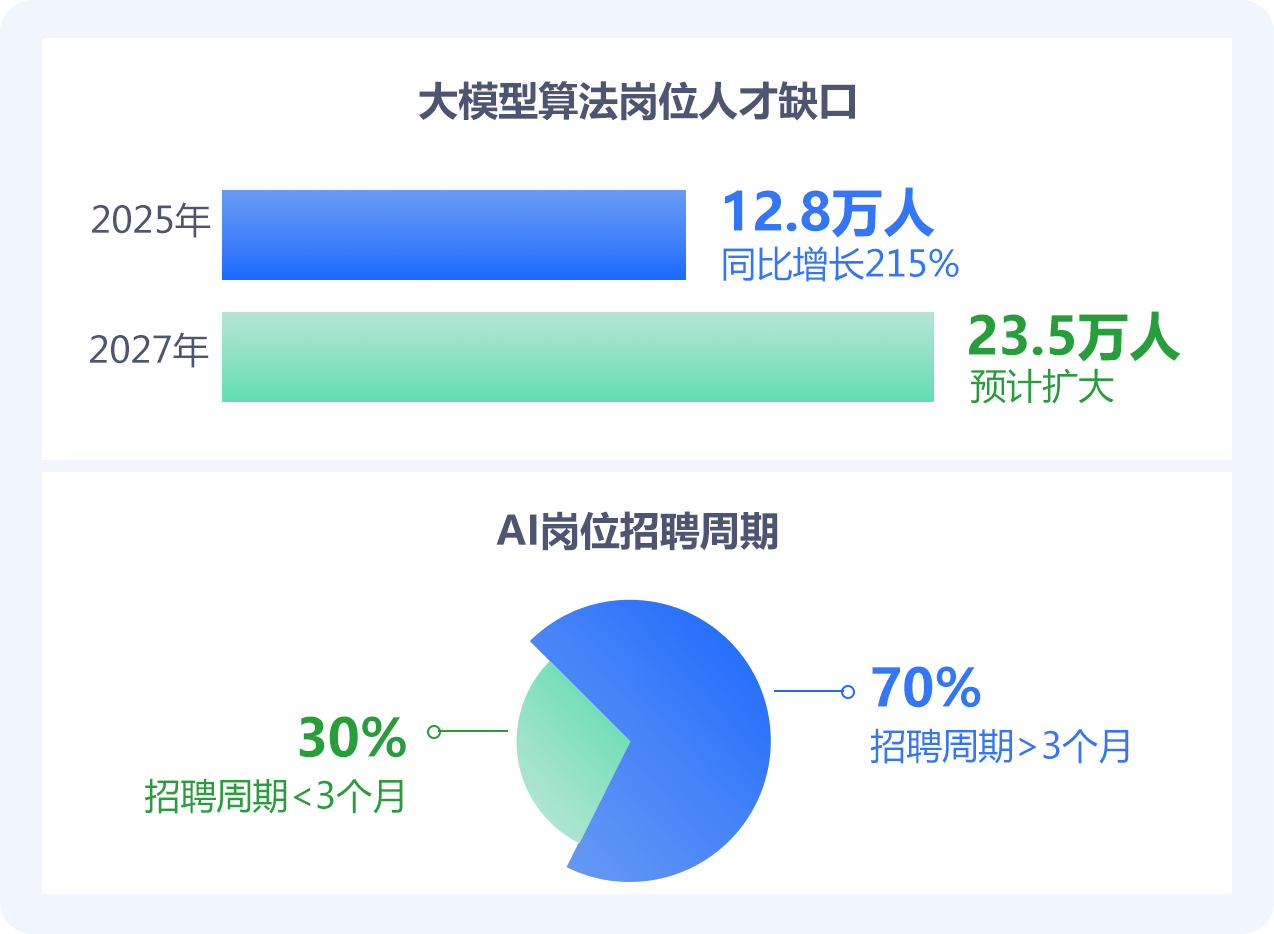




人才市场的 "超级风口"
2025年大模型算法岗需求同比增长215%,人才缺口达12.8万人,预计2027年将扩大至23.5万人,70%AI岗位招聘周期超过3个月,企业 "高薪难觅" 现象普遍。
数据来源:智联招聘《2024 人工智能人才趋势报告》
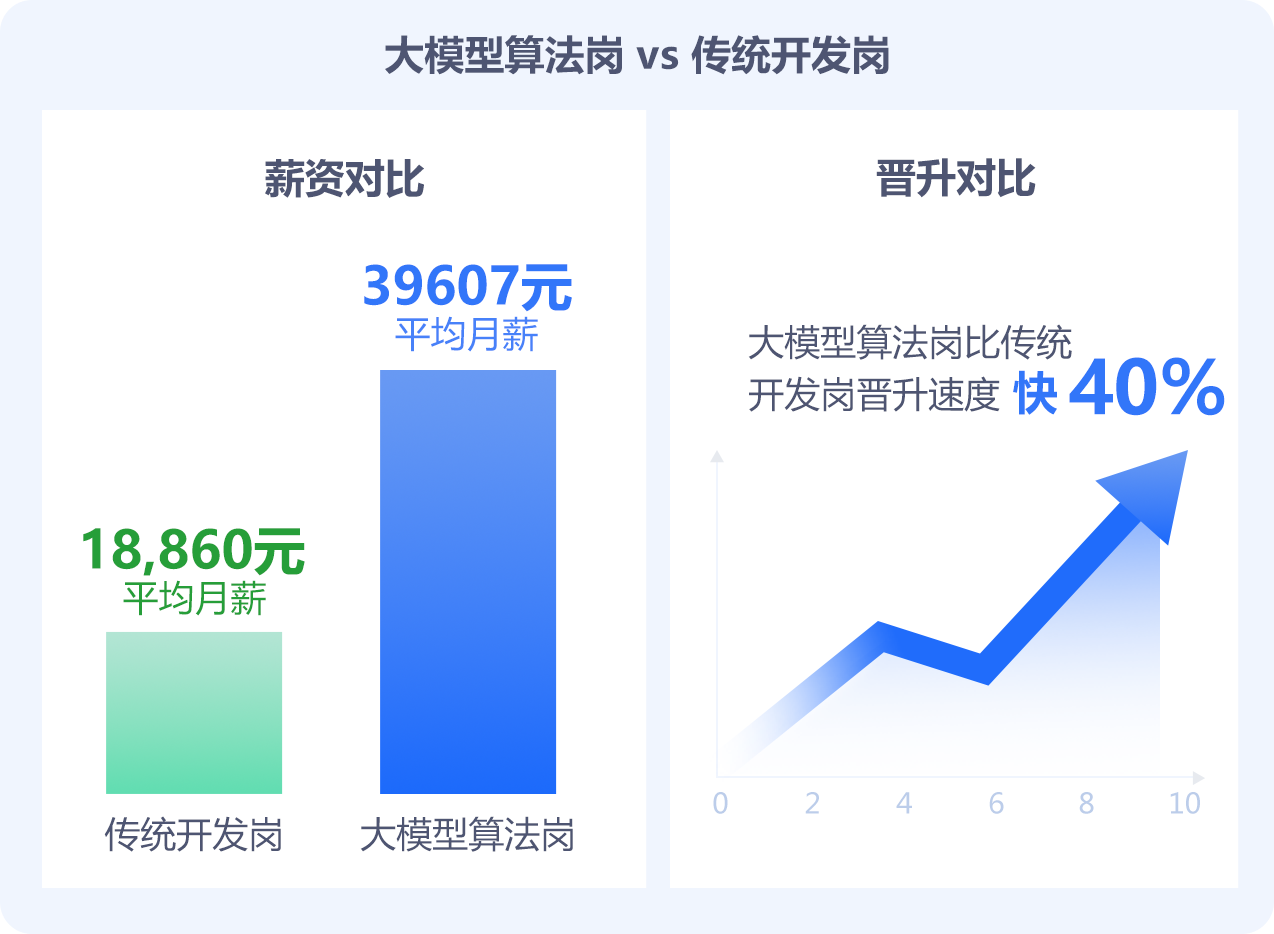
薪资与职业成长的 "超级加速器"
大模型算法岗平均月薪39,607 元,是传统开发岗的2.1 倍,应届生起薪 (15-30K) 已超普通岗 3-5 年经验水平。"3 年晋升 T6,5 年晋升T7"在头部企业已成常态,晋升速度比传统 IT 快 40%。
抢占 "红利窗口期" 的最佳时机
大模型正从 “实验室” 走向 “规模化应用”,2025年是企业落地元年,此时入门可抢占“早期红利”,成为行业“第一批吃螃蟹的人”;随着技术普及,未来入门门槛可能会提高(企业对技能要求更细分),现在转行能以更低成本积累竞争力。


金融行业

医疗健康行业
教育行业

内容创作与办公行业

生活服务行业









有自己的职业规划,且具有职业前瞻性,目标抢占AI赛道先机的学生群体。
计算机、数学、统计等相关专业学习效果更佳

零经验,但对人工智能或者大模型算法感兴趣,很看好相关行业发展。
希望借助技术风口实现职业 “弯道超车”,走向职业逆袭之路。

有基础编程能力的职场人 (Java / 前端 / 测试等)、对 AI 有热情的产品经理 / 运营、传统行业技术爱好者。
期待成功转型后,薪资能够得到提升和翻倍。

想要深耕行业,用 AI 重构业务能力的垂直领域,从 “业务执行者” 转向 “AI 赋能者”。
在职业发展上实现薪资翻倍、晋升加速。

扎实的
AI算法理论基础
-
深刻理解机器学习、深度学习、大模型的核心算法原理
-
掌握从传统ML到Transformer架构的技术演进逻辑
-
具备解决复杂AI问题的理论分析与建模能力
全栈的
工程实现能力
-
熟练使用PyTorch/TensorFlow等主流深度学习框架
-
掌握从数据处理到模型训练、优化、部署的完整工程链路
-
具备千亿参数大模型的分布式训练与推理加速能力
企业级的
应用开发能力
-
能够基于LangChain/LlamaIndex构建生产级AI应用
-
掌握RAG知识库、Agent智能体、多模态应用等前沿技术
-
具备将大模型技术与业务场景深度融合的产品化能力
高端的
性能优化能力
-
掌握GPU底层CUDA编程与算子优化技术
-
熟练使用模型量化、TensorRT、vLLM等推理加速技术
-
具备构建高并发、低延迟AI服务的系统架构能力

*以上数据来源boss直聘













-
机器学习工程师
-
深度学习算法工程师
-
计算机视觉(CV)工程师
-
自然语言处理(NLP)工程师
-
AI应用开发工程师
课程一、机器学习算法(必修)

-
数据预处理、特征工程、特征降维(PCA/LDA)
-
分类算法:KNN、决策树、朴素贝叶斯、逻辑回归、SVM
-
聚类算法:K-means、层次聚类、DBSCAN
-
协同过滤推荐算法
-
集成学习:随机森林、GBDT、XGBoost、LightGBM
-
泰坦尼克号获救预测(分类)
-
购物车推荐系统(协同过滤)
-
客户价值分析(聚类)
-
电商评论情感分析(NLP+分类)
-
图像分类识别系统(OpenCV+随机森林)
课程二、深度学习框架(必修)
-
神经网络基础:BP算法、激活函数、损失函数、优化器
-
CNN卷积神经网络:卷积层、池化层、经典网络架构
-
RNN循环神经网络:LSTM、GRU、Seq2Seq
-
PyTorch框架:Tensor、Autograd、nn.Module、DataLoader
-
TensorFlow框架:计算图、Keras API、TensorBoard
-
智能垃圾分类(CNN图像分类)
-
酒店评论情感分析(BiLSTM文本分类)
-
智能机器翻译(Seq2Seq+Attention)
-
新闻文本分类(TextCNN/LSTM)
课程三、NLP自然语言处理(必修)
-
中文分词、TF-IDF、Word2Vec词向量
-
文本分类、序列标注(NER命名实体识别)
-
BiLSTM+CRF模型、文本相似度计算
-
国家电网投诉分类系统(Word2Vec+LR、TextRCNN)
-
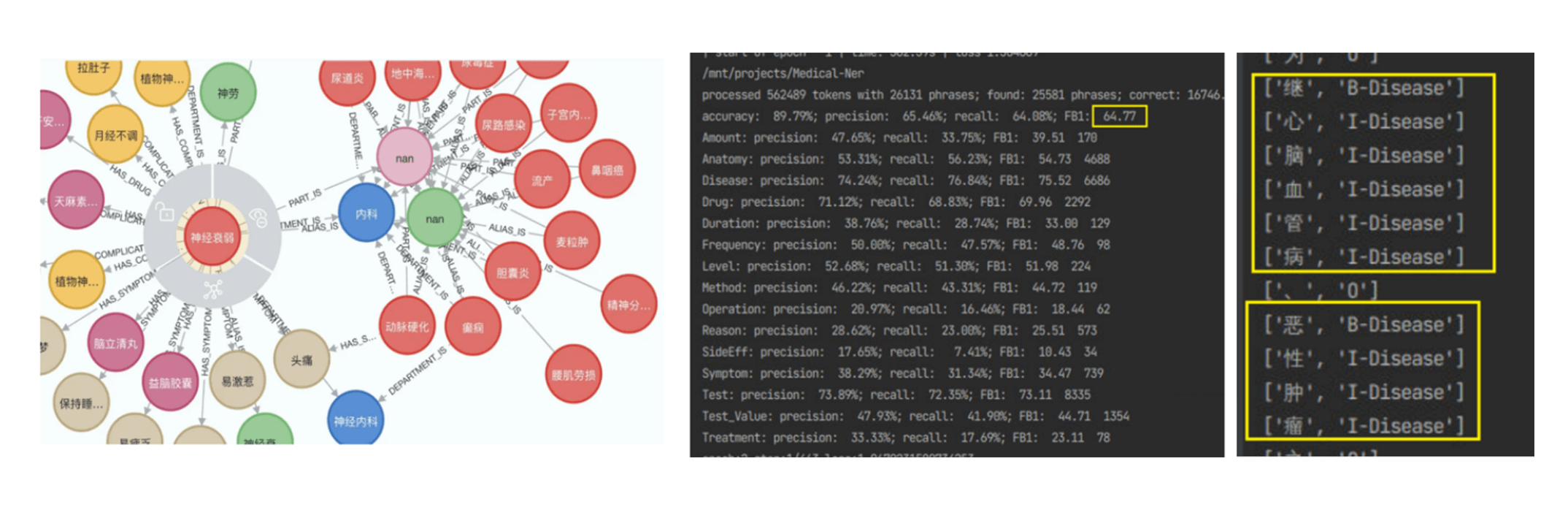
医疗命名实体识别(BiLSTM+CRF、构建糖尿病知识图谱)
课程四、知识图谱(必修)
-
Neo4j图数据库、Cypher查询语言
-
命名实体识别(NER)、关系抽取
-
知识推理、语义搜索、智能问答
-
武器知识图谱(Neo4j)
课程五、企业AI场景应用(必修)
-
零售精准营销预测系统(RFM模型)
-
电影推荐系统(SVD协同过滤)
-
文档自动分类系统(NLP+Word2Vec)
-
银行投诉分类系统(LSTM)
-
智能客服机器人(知识图谱+对话系统)
课程六、Transformer架构(必修)
-
Attention注意力机制、Self-Attention、Multi-Head Attention
-
Transformer完整架构:Encoder-Decoder、Position Encoding
-
Transformer在NLP任务中的应用:文本分类、序列标注、文本相似度、摘要生成、对话系统
阶段选修内容
-
YOLOv3人脸检测
-
CT肺结节检测
-
人脸识别平台
-
半监督学习、迁移学习、强化学习入门
-
语音识别(GMM-HMM、LSTM+CTC)
-
大数据+AI部署(Spark MLlib、TensorFlow Serving、TorchServe)
-
OpenCV图像预处理:剪裁、增强、特征提取
-
基于传统机器学习的图像分类(KNN、随机森林)
-
图像分类、目标检测、实例分割的深度学习原理与PyTorch/TensorFlow实现
-
YOLOv3、Mask R-CNN、RetinaFace+FaceNet等主流CV模型架构与训练
-
医学影像处理(DICOM、SimpleITK)与智慧医疗场景应用
-
源码解析、模型训练、超参数调优
-
工业部署:PyTorch→ONNX→TensorRT、CUDA加速、Triton Server
-
YOLO系列演进史、YOLOv11核心技术(C3K2、PANet++、TaskAlignedAssigner)
-
马尔可夫链与S序列建模基础
-
GMM-HMM混合模型原理及其在语音识别中的应用
-
语音识别基本流程与核心算法框架
-
基于LSTM的序列建模与文本分类实战
-
大模型算法工程师
-
LLM训练与微调工程师
-
大模型推理优化工程师
-
AIGC应用开发工程师
-
生成式AI系统架构师
课程七、大模型核心技术(必修)
-
大模型发展史:BERT→GPT→ChatGPT
-
Transformer深度剖析
-
分词算法:BPE、WordPiece、SentencePiece
-
位置编码:绝对/相对/旋转位置编码(RoPE)
-
解码策略:贪心、Beam Search、Top-k/Top-p采样
-
Finetune微调理论、RLHF强化学习原理
课程八、大模型优化与微调(必修)
-
Prompt工程: Prompt设计、Few-Shot、思维链(CoT)
-
PEFT参数高效微调: LoRA、QLoRA、Prefix-Tuning、P-Tuning、Adapter
-
模型量化: INT8/INT4/FP16、PTQ、QAT、GPTQ、AWQ
-
模型评测: Perplexity、BLEU、ROUGE、MMLU、C-Eval、HumanEval
-
性能加速: KV-Cache、Flash Attention
-
Qwen大模型微调实战: 使用Swift框架完成SFT、RLHF、DPO、GRPO等多种微调方法
课程九、主流大模型架构(必修)
-
GPT系列:GPT-3.5、GPT-4
-
LLaMA系列:LLaMA、LLaMA2、LLaMA3
-
Qwen系列:通义千问
-
DeepSeek系列:DeepSeek-V2/V3、DeepSeek-R1
-
ChatGLM系列、Claude、百川、文心一言
-
领域专用大模型:医疗、金融、法律、代码大模型
-
企业模型选择策略:性能、成本、场景适配
阶段选修内容
-
GPU架构与CUDA编程、GEMM矩阵优化
-
LLM完整训练流程:PreTraining、SFT、RLHF
-
分布式训练:数据并行、模型并行、流水线并行
-
推理加速:量化、轻量级LLM、端云协同
-
DeepSeek技术解密:MLA、MoE、GRPO、FP8训练
-
多模态:CLIP、BLIP、Qwen-VL
-
企业级RAG平台(端云协同、降本60%)
-
智能对话助手
-
大模型推理部署工程师
-
模型优化与性能调优专家
-
AI基础设施工程师
-
LLM服务架构师
-
GPU加速与系统优化工程师
大模型推理部署与加速(必修)
-
推理框架: vLLM(PagedAttention、Continuous Batching)、TensorRT-LLM(量化INT8/INT4)、llama.cpp
-
模型服务化: FastAPI服务构建、负载均衡、流式输出、并发控制、Docker/K8s部署
-
性能优化: KV-Cache复用、投机解码、批处理优化、显存优化
-
分布式推理: 张量并行、流水线并行、Ray Serve、Triton Inference Server
阶段选修内容
阶段项目
-
vLLM高并发推理服务: 构建生产级API服务
-
TensorRT-LLM加速: INT8/INT4量化、多GPU推理
-
企业级模型服务平台: 多模型路由、监控、容器化部署
-
RAG 架构师
-
AI Agent 工程师
-
多模态 AI 工程师
-
智能对话系统开发工程师
-
AIGC 应用研发工程师
课程十、RAG检索增强生成(必修)
-
知识库构建: 文档解析、文本分块、知识图谱、向量化
-
向量检索: Embedding模型(BGE/M3E)、向量数据库(Faiss/Milvus/Chroma)、混合检索
-
检索优化: 意图识别、相关性过滤、重排序(Rerank)
-
Prompt工程: RAG场景Prompt设计、上下文管理、查询改写
-
集成学习:随机森林、GBDT、XGBoost、LightGBM
-
生成优化: LLM集成、流式输出、质量控制
-
评估监控: 准确率/召回率、A/B测试
-
智能文档管理系统: 多模态输入(图文)、多路召回、RoBERTa+Faiss、Wiki知识融合
-
医疗问答系统(知识图谱+RAG): Neo4j图数据库、向量检索+图谱查询、医学知识推理
-
汽车知识问答系统: 汽车垂直领域、车型识别、故障诊断、多模态输入
课程十一、AI Agent智能体(必修)
-
Agent理论: ReAct范式、思维链(CoT)、自我反思、任务规划
-
工具使用: Function Calling、API调用、工具选择、错误处理
-
Agent框架: LangChain Agent、AutoGPT、MetaGPT、LangGraph工作流
-
记忆系统: 短期记忆(对话历史)、长期记忆(向量库)、个性化管理
-
多Agent协作: 通信机制、任务分解、协作策略
-
零代码Agent开发(Coze平台): 可视化工作流、知识库、插件集成、多渠道发布
-
智能投资助手: 记忆系统、工具集成(行情API/财报)、规划能力、风险控制
课程十二、多模态基础技术(必修)
-
视觉编码器: ViT(Vision Transformer)、CLIP视觉编码器
-
跨模态对齐: CLIP对比学习、图文检索
-
多模态融合: BLIP/BLIP-2、Flamingo
-
图像生成: Stable Diffusion、FLUX、ControlNet、文生图/图生图
课程十三、多模态大模型应用(必修)
-
主流多模态大模型: DeepSeek-VL、LLaVA、InternVL、GLM-VL、Qwen-VL、Qwen-omini
-
模型评测: MMBench、MMMU评测基准
-
部署优化: 模型量化、推理加速
-
模型训练: 视觉-语言对齐、指令微调
-
文生图实践: Stable Diffusion、LoRA微调
-
电商多模态商品检索: CLIP跨模态检索、以图搜图、语音搜索
-
地理位置识别系统: 地标识别、地理编码、地理知识图谱
-
用户意图理解系统: 融合文本/图像/语音、意图分类、情感分析
-
内容安全审核平台: 图像/文本/视频/音频审核、YOLO检测、OCR识别
-
视频情感分析系统: 表情识别、语音情感、文本情感、时序建模
阶段选修内容
-
LlamaIndex RAG开发、Text2SQL
-
LangChain核心组件:Models、Prompts、Chains、Memory、Tools、Agent
-
LCEL表达式语言、Retrieval检索增强
-
LangGraph工作流编排、MCP协议
-
多智能体协作诊断系统(LangGraph)
-
YOLO系列演进史、YOLOv11核心技术(C3K2、PANet++、TaskAlignedAssigner)
-
源码解析、模型训练、超参数调优
-
工业部署:PyTorch→ONNX→TensorRT、CUDA加速、Triton Server
其他选修课
-
机器学习数理基础(数理统计、高等数学)
-
半监督学习、迁移学习、强化学习入门
-
大数据+AI分布式部署(Spark MLlib、模型部署)